
ChatGPT大语言模型有什么缺点?
缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...
缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...

缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...
关键一:数据 训练数据主要是所谓的语料库。今天的很多语言模型的语料库主要有以下几种: Books:BookCorpus 是之前小语言模型如 GPT-2 常用的数据集,包括超过 11000 本电子书。主要包括小说和传记,最近更新时间是 20...

基于上述的第三点缺点,研究人员就找到了一个叫 Chain of Thought 的技巧。 这个技巧使用起来非常简单,只需要在问题的结尾里放一句 Let‘s think step by step (让我们一步步地思考),模型输出的答案会更加准...
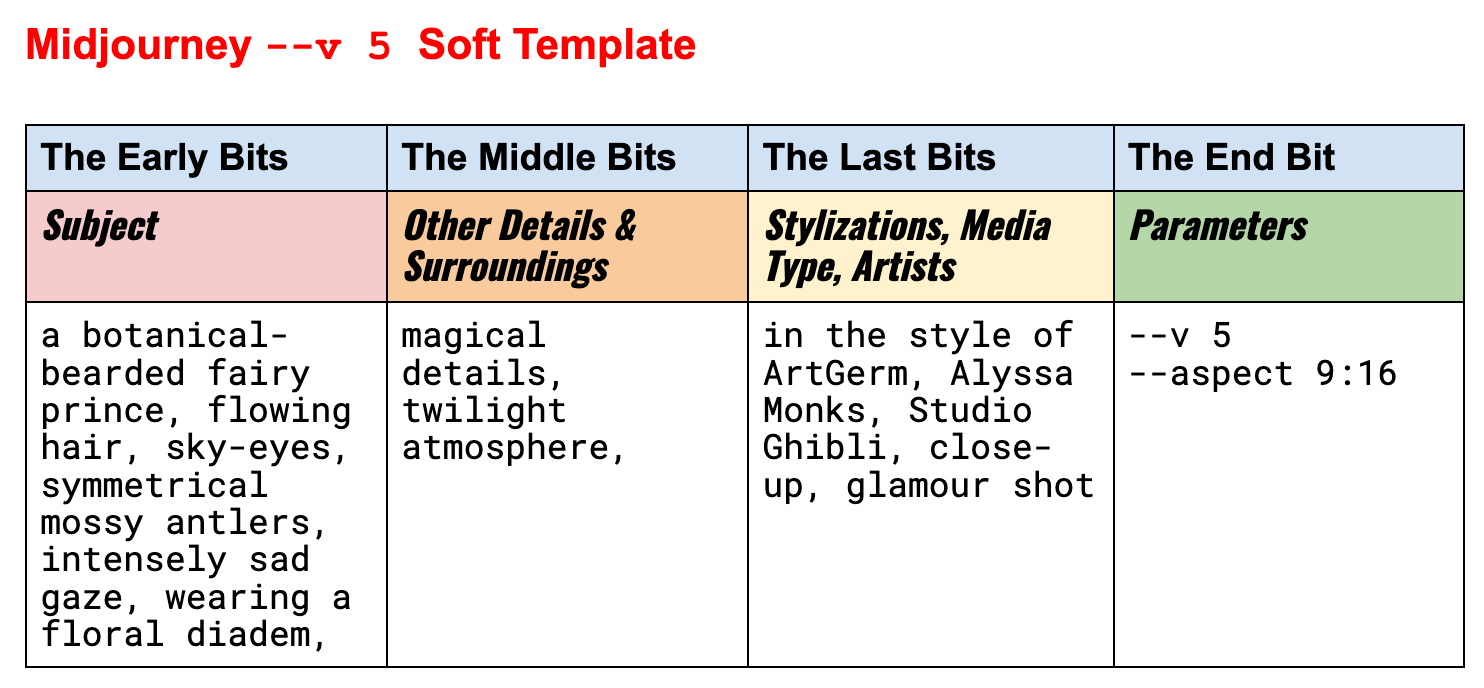
官方框架 在做总结前,我想先介绍下 Midjourney 官方的框架: 官方的模板很简单,分成四个部分: 主体 细节 & 背景 风格、媒介、艺术家 参数 我的总结 其实按照官方模板写,你已经能超过 90% 的初学者,但根据我的实...

缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...

缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...

缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...
关键一:数据 训练数据主要是所谓的语料库。今天的很多语言模型的语料库主要有以下几种: Books:BookCorpus 是之前小语言模型如 GPT-2 常用的数据集,包括超过 11000 本电子书。主要包括小说和传记,最近更新时间是 20...
缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...


