
Midjourney text prompt 技巧十三:善用灯光
坦诚地跟大家说,我不是设计师,也不是摄影师(而且我非常不擅长摄影),所以我仅能跟大家分享一下基础内容,因为这个对我来说,太多过程性知识了,不实际操作过,根本不知道有什么。 言归正传,摄影中,常用摄影灯光有以下几种: 主灯 (Key Ligh...
坦诚地跟大家说,我不是设计师,也不是摄影师(而且我非常不擅长摄影),所以我仅能跟大家分享一下基础内容,因为这个对我来说,太多过程性知识了,不实际操作过,根本不知道有什么。 言归正传,摄影中,常用摄影灯光有以下几种: 主灯 (Key Ligh...

很多人把 AI 生成图片比喻为炼丹,我觉得非常贴切,很多时候,也不知道为啥,在 prompt 里加一点神秘配方,图片就会很不一样。 不过我觉得虽然过程很像炼丹,但并不代表我们需要像古人那样,用撞大运的方式炼制丹药。我认为目前使用 Midjo...
注意:这个技巧,我个人觉得未来潜力比较大,但目前 Midjourney 的实现效果还比较一般,效果得不到保证。官方的社区的帮助文档也提到这个功能在 V5 非常不稳定。详细可以看看我整理的 Midjourney 官方 FAQ 一章。 你可能遇...

首先需要注意,Midjourney 支持大部分的艺术运动,但在艺术家的支持上,相对来说比较少,经过网友们的不懈努力,截止到 3 月 31 日,V4 已知支持的艺术家有 2000 多位,V5 有 100 多位。 其中在榜的 Logo 设计师,...

前面生成的 logo ,有一些估计各位会觉得平平无奇,比如 Lettermark Logo,原因并不是 Midjourney 能力不强,而是我们给的指令太少了,只要在 prompt 里加几个单词,就能生成不一样的 Logo: 左边四个的 p...
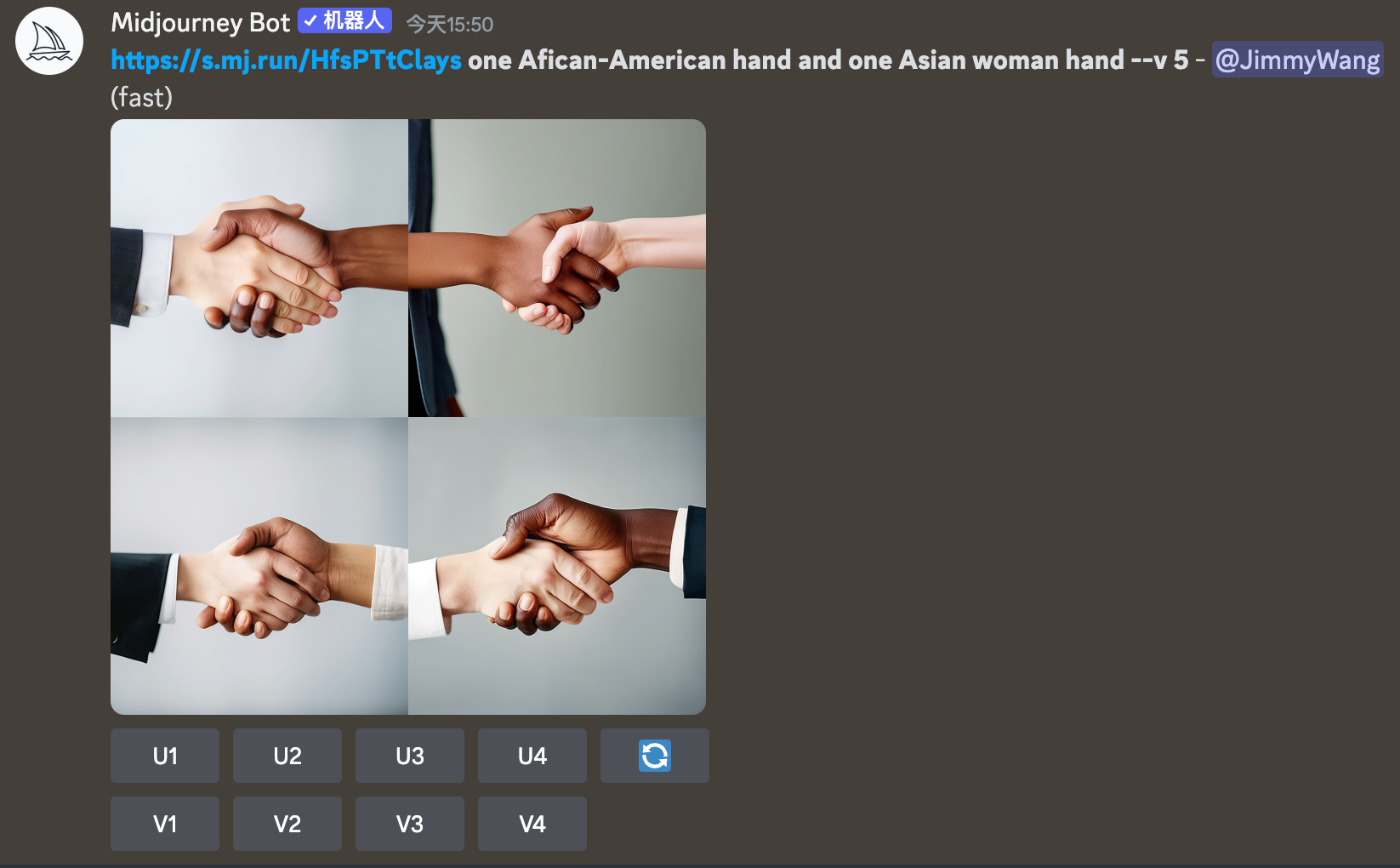
在 Stock Photo 场景里,还有一个非常厉害的技巧,这个方法我一开始觉得不太适合教,因为这个对 Stock Photo 库影响太大了 ? 但本着工具中立的原则,并且这个技巧,其实在很多场景都能用(比如生成头像等),所以还是觉得有必要...

我认为学习图片类的 prompt,跟学习画画是类似的,最好的学习方法不是直接用模板。 而是拿真图,或者别人生成的图来临摹。英文不好,也可以先写中文,然后让 ChatGPT 翻译。当你临摹了几张后,你就会慢慢搞懂如何做出类似的图了。 拿上面的...
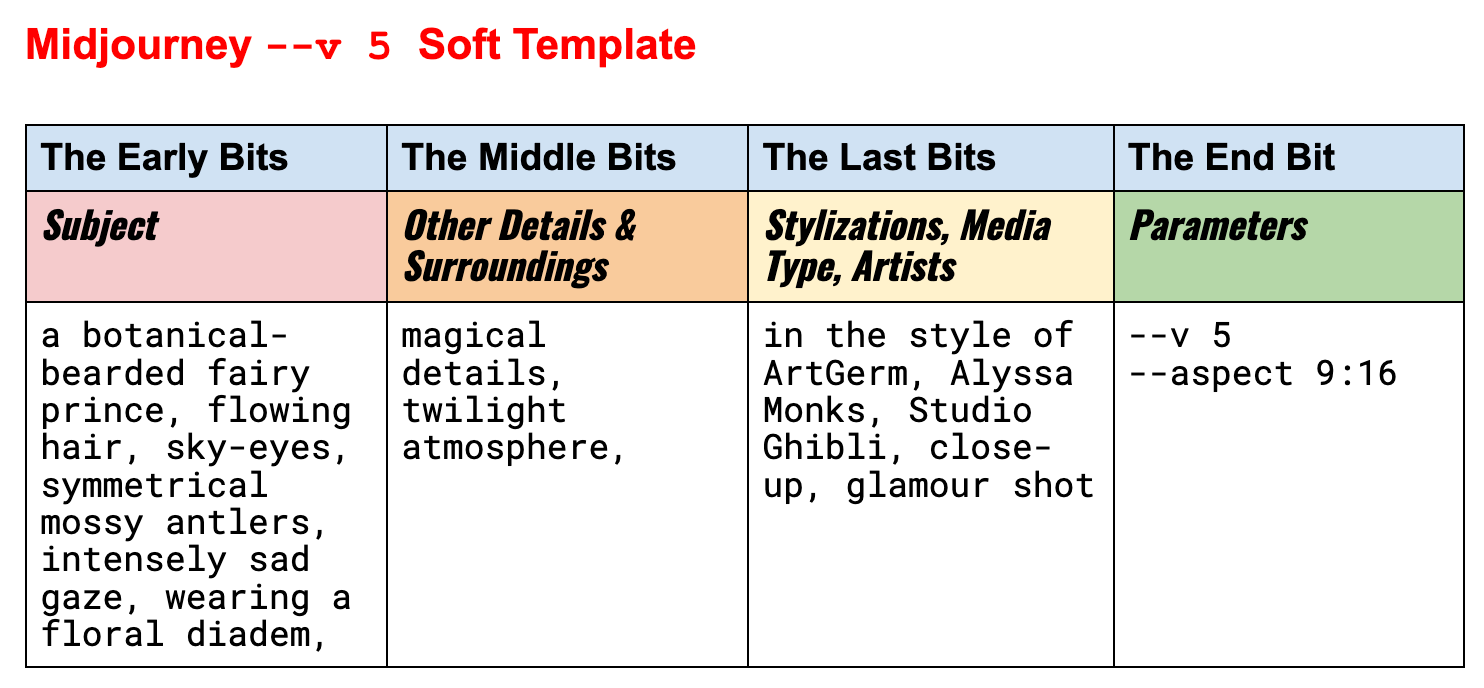
官方框架 在做总结前,我想先介绍下 Midjourney 官方的框架: 官方的模板很简单,分成四个部分: 主体 细节 & 背景 风格、媒介、艺术家 参数 我的总结 其实按照官方模板写,你已经能超过 90% 的初学者,但根据我的实...

缺点一:结果高度依赖训练语料 正如我前面提到的,当今的语言模型,即使发展了四个版本,但依然没有脱离「概率计算」,本质上来说它们的核心原理就是「利用已有的信息来预测其他信息」。 那这就意味着,大语言模型其实并没有意识,也不知道对错,其生成的...

关键一:数据 训练数据主要是所谓的语料库。今天的很多语言模型的语料库主要有以下几种: Books:BookCorpus 是之前小语言模型如 GPT-2 常用的数据集,包括超过 11000 本电子书。主要包括小说和传记,最近更新时间是 20...


