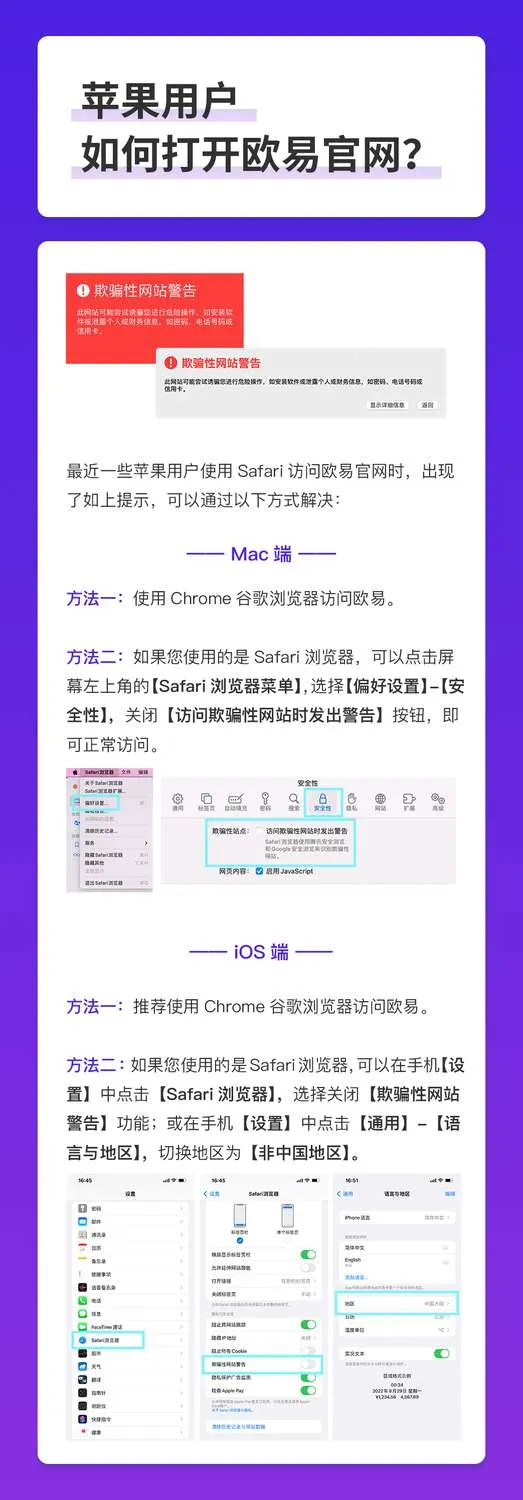
RLHF的实际工作原理以及我们何时能在开源项目中看到它
本文讨论了强化学习从人类反馈中学习(RLHF)为什么有效的问题,作者认为RLHF在两个条件下才能长期有效:第一,需要有一些信号表明仅应用基本监督学习不起作用,即成对偏好数据;第二,它也在需要缓慢改变以实现成功的复杂优化景观上表现出色。此外,本文还探讨了RLHF的数据和优化方面,以及其在遇到困难时的应用。作者指出,RLHF在数据方面需要非常准确和可靠的数据,而在优化方面需要匹配分布以获得最佳效果。此外,本文还探讨了RLHF的规模问题,以及一些仍需解决的问题。